On Handling PDF Files in QDA Software
Using PDFs in QDA software is not a new feature, but working with this particular type of file is still somewhat tricky. In this overview I’ll outline general issues with the use of PDFs in QDA software, and I’ll briefly compare import/linking options of PDFs in MAXQDA, NVIVO & ATLAS.TI.
A general note on using PDFs
Although MAXQDA, NVIVO & ATLAS.TI offer the import and/or linking of PDFs, users should transform their PDFs into .docs or .RTF files before importing – due to issues with character recognition, issues with mobility & performance, coding practice, and export.
PDF support is advertised as a feature in modern QDA software; but due to ongoing issues in terms of performance & user-friendliness, I would strongly advise users to convert their files into text documents (e.g. RTF, DOCX) wherever possible. Although QDA software can be used as a library for your PDF literature, specialized programs are much more powerful with this task (e.g. Zotero, Mendeley, RefWorks, EndNote etc).
The issue with(out) OCR
You will only be able to highlight & code text in a PDF if the document ran through OCR (optical character recognition, see Wikipedia) beforehand. Most PDFs (e.g. journal articles) these days already come like that, but the scan of the copy of your advisor’s advisor’s dissertation microfiche data-set probably won’t. If the characters in your files are not already recognized in the PDF, you will be only able to code a PDF as it were a picture (in software in which you can tag/code pictures). This will heavily influence how your data is represented in retrievals, and it will greatly impact the appearance of the export of your retrievals. Instructions on converting PDFs can be found all over the web; here’s a how-to from the University of Iowa.

Non-OCR’d PDF file in NVIVO.
File: Ochs, E. (1979). Transcription as theory. Developmental pragmatics, 10(1), 43–72.
Issues with mobility & performance
PDFs can be linked to project files, or integrated into project files. If they are linked, it is important that the place where the PDFs are saved stays the same. For example, if you save your PDFs in C:\library\pdfs (or if the program does this for you), the software will always look for this path when you open a PDF in the QDA software. If you move your files or modify the path names, the link is broken; if you’re working on a different computer, you won’t be able to see your linked data. If you link PDFs from a portable device, (e.g. a USB stick), you’ll have to make sure that the location of the stick (e.g. F:\ ) is the same on each computer. Otherwise the software won’t know where the PDFs are. All of this means that the whole project is not as easily transportable anymore. One of the great strengths of QDA software is that all your stuff lives in one place. Linking files takes some of this strength away.
But what about just importing the PDF into the project file? If a program allows PDFs to be integrated into the project file, this main file will get very large very quickly. This will make it harder to send the project file to other researchers, and it will cause the QDA software to run sluggishly, or even crash more often.
Issues with coding
Coding PDFs in QDA software feels a bit like putting a thread through a needle one a train. Even with OCR supported files, highlighting text across page boundaries can be tedious – especially if the file has headers and footers. Also, files that have text in several columns can be funky to code too; ff you’ve used the Adobe Reader for highlighting PDFs, you’ll probably know what I’m talking about.
This being said: While this is a non-issue if you deal with just a few PDFs, these things can become quite frustrating in the long run. Text files such as .docs and .rtfs give you much more ease of use. Given that you might stare at your data for months (or years!), it is worth transforming data into text files beforehand. Note also that not all PDFs can be coded and viewed in QDA software (cf. the software comparison below); for example linked PDFs cannot be annotated in NVIVO.
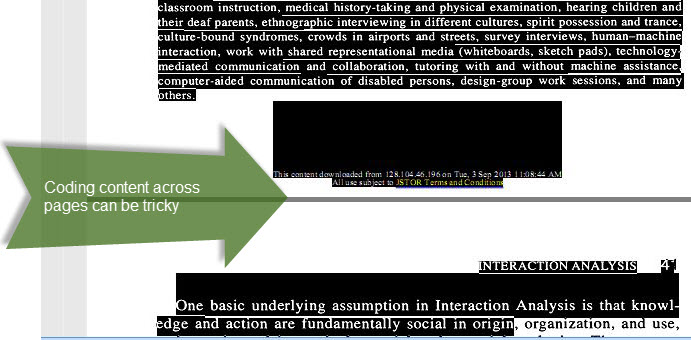
Issues with highlighting data across pages. Screenshot from MAXQDA.
Jordan, B., & Henderson, A. (1995). Interaction Analysis : Foundations and Practice. The Journal of the Learning Sciences, 4(1), 39–103.

Issue with selecting larger amounts of data while scrolling. Screenshots from NVIVO.
File: Troseth, G.L. et al. (2006). Young Children’s Use of Video as a Source of Socially Relevant Information. Child Development, 77(3), 786-799.

Issue with visual correspondence of coding strip with coded content. Screenshot from MAXQDA.
File: Troseth, G.L. et al. (2006). Young Children’s Use of Video as a Source of Socially Relevant Information. Child Development, 77(3), 786-799.
Issues with export
PDFs will not have paragraph numbers – if you do fine-grained analysis and your PDFs do not come with line or paragraph numbers, the export will not supply information on where exactly a snippet is (aside from showing the source name & source folder, if applicable). If you work a lot with fine-grained analytic procedures, and if you work a lot on paper, this should be kept in mind.
Overview: PDF import, linking & handling in NVIVO, MAXQDA, ATLAS.TI
NVIVO: Import and/or linking of PDFs is possible. Only if you import PDFs you can code & annotate them. PDFs that are linked to the project file cannot be annotated & coded. In this latter case, you’re basically creating a blank document in NVIVO, and you link the PDF as an outside source to it. The PDF will not open in NVIVO, but opened in a PDF viewer (e.g. Adobe Reader). Unlike in the case of MAXQDA & ATLAS.TI, linked files are not automatically archived in a library – you should therefore make sure to store your PDFs in a special folder before you link them.
MAXQDA: Import of PDFs and/or linking of PDFs is possible. In both scenarios, the PDF will be opened within MAXQDA, and it can be coded and annotated. If a PDF is linked, it will be copied & stored in a special library folder by MAXQDA. (in my case this would be: C:\Users\cs\Documents\MAXQDA_Externals ; this folder can be changed in Project->Options)
ATLAS.TI: PDFs can be linked to a project file (but not imported, since ATLAS’ project structure works a bit differently). The linked PDFs are opened in ATLAS.TI; they can be annotated & coded within the software. Upon adding the PDF, a copy of the file is stored in a special library folder by ATLAS.TI. (In my case this would be: C:\Users\cschmieder\AppData\Roaming\Scientific Software\ATLASti\Repository\Managed Files\ ; this folder can be changed in Documents-> Data Source Management -> Library Manager -> Extras -> Set Library Location).
This post was made possible thanks to the support of MERIT Library, School of Education, UW-Madison. It was first posted here.